





โลกที่เปลี่ยนแปลงรวดเร็ว เทคโนโลยีพัฒนาต่อเนื่องในทุกทิศทาง เร็วๆ นี้เอง มีรายงานประจำปีชิ้นหนึ่งที่เป็นประโยชน์ต่อการทำความเข้าใจความเป็นไปในวงการนี้ ชื่อว่า Emerging Technology Hype Cycle จัดทำโดยบริษัทวิเคราะห์วิจัยข้อมูลที่ชื่อ การ์ตเนอร์ (Gartner)
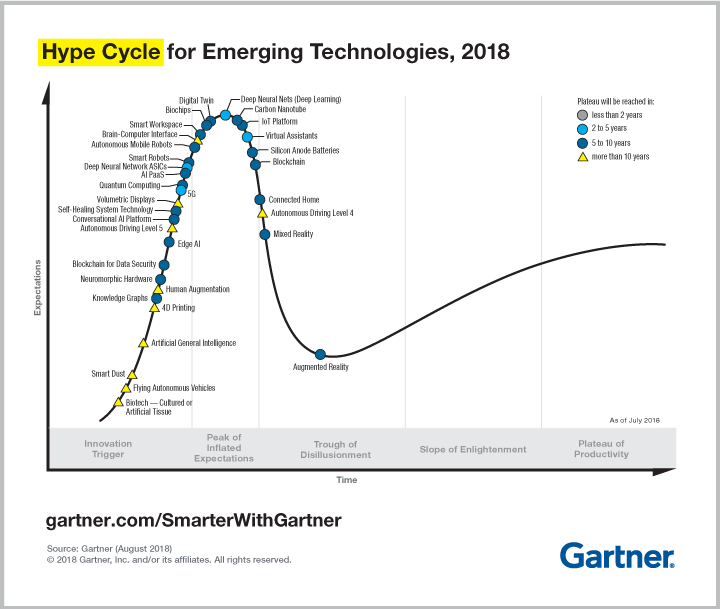
[รูป: Hype Cycle for Emerging Technologies, 2018]
เขาว่าในภาพรวมแล้ว เทคโนโลยีแบ่งเป็น 5 ช่วงเวลา จากช่วงเริ่มต้นที่มีการค้นคว้าและผลิตเทคโนโลยีใหม่ จากนั้นก็เป็นช่วงพีค หรือจุดสูงสุดของความคาดหวังที่หลายคนมีต่อเทคโนโลยีใหม่ ต่อมา เป็นช่วงเวลาที่เมื่อเทคโนโลยีใหม่เหล่านี้ต้องใช้เวลาอีกสักพัก ก่อนจะเข้าสู่ช่วงของการปรับปรุงให้เข้ากับบริบทหน้างานจริงให้ใช้งานได้ในวงกว้าง ซึ่งจะเป็นช่วงเวลาที่ความคาดหวังลดลงอย่างมาก สุดท้าย คือ จะมีเพียงแค่เทคโนโลยีบางตัวเท่านั้นที่สามารถนำไปประยุกต์ใช้งานได้จริงด้วยราคาที่เหมาะสมและสามารถสร้างมูลค่าในธุรกิจได้
จากรายงานปี 2018 ของการ์ตเนอร์ ระบุว่า เวลานี้ เทคโนโลยีด้านการเรียนรู้ของเครื่องจักร (Machine Learning หรือ Deep Learning) ถือว่ายังอยู่ในช่วง ‘พีค’ ของความคาดหวัง แถมยังอยู่ในจุดสูงสุดของกราฟ ซึ่งเป็นสิ่งที่หลายคนสัมผัสได้ผ่านทั้งข่าวและงานวิจัยที่ตีพิมพ์ออกมาแทบทุกวัน
แต่สิ่งที่จะต้องจับตาต่อไปก็คือ เทคโนโลยีนี้จะสามารถประยุกต์ใช้จริงในวงกว้างได้เพียงใด มีประโยชน์ในเชิงธุรกิจและสังคมมากน้อยแค่ไหน และองคร์กรหรือประเทศจะรับมืออย่างไร
จากรายงานประเมินว่า ในเวลาอันสั้น ประมาณ 2-5 ปี เราน่าจะได้เห็นผลลัพธ์ของ Machine Learning กันอย่างจริงจัง และมีคำตอบต่อคำถามข้างต้นได้ชัดเจนมากขึ้น
จะทำอย่างไรให้เข้าใจผลกระทบที่มากับเทคโนโลยี
ถึงแม้ว่า Machine Learning จะอยู่ในช่วงพีค แต่มันก็เหมือนเทคโนโลยีใหม่อื่นๆ ที่หากคนที่นำไปใช้ไม่ได้ศึกษาเข้าใจถี่ถ้วนถึงความเป็นมาและผลกระทบของมันก็อาจทำให้เกิดผลเสียได้
กรณีศึกษาล่าสุดคือ องค์กร ACLU (American Civil Liberties Union) ของสหรัฐอเมริกา ซึ่งทำงานเกี่ยวข้องกับกฎหมายและสนใจเรื่องการปกป้องสิทธิของประชาชน ได้ทดลองใช้ซอฟต์แวร์ตรวจจับใบหน้าของวุฒิสมาชิกเพื่อวัดความแม่นยำของซอฟต์แวร์ ว่าสามารถหาชื่อของเจ้าของใบหน้าในรูปตัวอย่างได้ถูกต้องหรือไม่
การทดลองนี้ ACLU ใช้บริการจากแอมะซอนที่ชื่อ Rekognition ซึ่งเป็นซอฟต์แวร์ที่ช่วยวิเคราะห์วิดีโอหรือภาพโดยใช้เทคนิค Deep Learning เข้ามาช่วย ซึ่งผลน่าจะมีความแม่นยำกว่าการวิเคราะห์ภาพแบบปกติ
แต่ผลลัพธ์ที่ออกมาพบว่า ซอฟต์แวร์ยืนยันตัวตนของวุฒิสมาชิกจำนวน 28 คนผิดพลาด โดยโปรแกรม ‘คิดว่า’ บุคคลเหล่านี้เป็นบุคคลอื่นที่เคยถูกจดจำเพราะมีประวัติอาชญากรรม
จากเหตุการณ์นี้ แอมะซอนชี้แจงว่า ในการทดลองของ ACLU อาจตั้งค่าความมั่นใจ (Confidence Level) ที่ต่ำเกินไป ในการทดลองใช้ค่านี้อยู่ที่ 80% ซึ่งแอมะซอนแจ้งว่าเหมาะสมกับรูปภาพทั่วไป เช่น เก้าอี้ สัตว์ หรือฮอตด็อก เป็นต้น แต่ในกรณีนี้ที่อาจมีการใช้ควบคุมทางกฎหมาย แอมะซอนกล่าวว่า ควรเพิ่มค่าความมั่นใจให้สูงกว่า 95% เพื่อให้โปรแกรมแม่นยำกว่าปกติ
สุดท้าย แอมะซอนย้ำว่า แม้โปรแกรมดังกล่าวช่วยลดภาระงานของคนได้ เช่นใช้ช่วยหาหรือยืนยันเด็กที่สูญหาย แต่ถึงอย่างไร ซอฟต์แวร์นี้ก็ยังต้องอาศัยมนุษย์เข้ามาช่วยยืนยันหรือตัดสินใจ
ตัวอย่างนี้อาจเป็นหนึ่งในหลายๆ เรื่องราวที่จะได้อ่านกันอย่างต่อเนื่องในช่วง 2-3 ปีข้างหน้า เพราะคงมีหลายองค์กรนำ Machine Learning เข้าไปใช้ และสร้างผลลัพธ์ออกมา ไม่ว่าจะให้ประโยชน์หรืออาจให้ผลลัพธ์อื่นที่อยู่นอกเหนือความคาดหวังก็ได้
ในด้านเทคโนโลยี งานลักษณะนี้ก็คงมีการวิจัยและทดลองอย่างต่อเนื่องเพื่อให้เกิดความแม่นยำมากขึ้น แต่อีกมิติหนึ่งคือ จะออกแบบกฎเกณฑ์ด้านสังคมหรือกฎเกณฑ์อื่นๆ ให้เข้ามาช่วยเสริมให้การใช้เทคโนโลยีนี้เป็นไปอย่างมีประสิทธิภาพได้อย่างไร ถือเป็นเรื่องใหม่ที่ท้าทายนักคิดนักนโยบายอย่างยิ่ง
ความรับผิดของอัลกอริธีม
ในวงการมีการพูดถึงเรื่องความโปร่งใสของที่มาที่ไปในการคิดอัลกอริธึม (Algorithmic Transparency) เพื่อวิเคราะห์หรือคาดการณ์เหตุการณ์บางอย่าง แนวความคิดนี้คล้ายกับที่ เอมมานูเอล มาครง ประธานาธิบดีประเทศฝรั่งเศสเคยกล่าวไว้ ในช่วงที่เกิดเหตุการณ์เคมบริดจ์ แอนะลีติกาเมื่อช่วงต้นปี จุดประสงค์คือ เพื่อให้มีการเปิดเผยวิธีคิด ลดความเหลื่อมล้ำทางด้านเทคโนโลยี และในขณะเดียวกัน ก็เพิ่มขีดความสามารถของอัลกอริธึมในภาพรวม โดยทีมงานหรือบริษัทหนึ่งๆ สามารถต่อยอดหรือพัฒนาเพิ่มเติมต่อจากโปรแกรมซอฟต์แวร์เวอร์ชันก่อนหน้าได้
ความโปร่งใสของอัลกอริธึมอาจฟังดูดี แต่ในเชิงธุรกิจแล้วยากต่อการบังคับใช้ เนื่องจากแต่ละบริษัทต้องใช้ทรัพยากรทั้งเงินทุนและแรงคนในการคิดค้นอัลกอริธึมที่มีความแม่นยำขึ้นมา หากต้องเปิดเผยให้คนภายนอกได้รู้ในวงการ ก็อาจไม่เป็นผลดีต่อการทำธุรกิจขององค์กรนั้นๆ แนวความคิดเรื่องความโปร่งในของอัลกอริธึมอาจใช้ได้ในบางกรณีเท่านั้น
แนวความคิดคล้ายกับความโปร่งใสของอัลกอริธึมคือ Algorithmic Explanability หรือความสามารถในการอธิบายได้ว่าอัลกอริธึมใช้หลักการอะไรในการตัดสินใจ และแจกแจงได้ว่าทำไมถึงเกิดผลลัพธ์แบบหนึ่งๆ เมื่อป้อนข้อมูลเข้าไปในโปรแกรมคอมพิวเตอร์
มหาวิทยาลัยหลายแห่งทำวิจัยเรื่องนี้ แต่ต้องยอมรับว่าหัวข้อนี้ยังเป็นเรื่องที่ยากมาก ตัวอย่างคลาสสิกคือกรณีของ AlphaGo ที่สามารถเอาชนะแชมป์โลกเกมโกะได้ โดยที่แม้แต่คนที่สร้าง AlphaGo ขึ้นมายังไม่สามารถอธิบายวิธีคิดหรือเหตุผลในการเดินแต่ละหมากของโปรแกรมได้ ในโลกของ Deep Learning ที่ข้อมูลไหลเข้าไปในอัลกอริธึมหลายสิบหลายร้อยชั้นเพื่อหาความสัมพันธ์และทำการคาดการณ์ให้ได้ผลลัพธ์ที่แม่นยำที่สุด มีการคิดที่ซับซ้อนมากจนคนเราไม่สามารถเข้าใจได้ การอธิบายว่าเกิดอะไรขึ้นข้างในยิ่งเป็นสิ่งที่ท้ายอย่างมาก
ในทางกลับกันหากต้องการให้อัลกอริธึมอธิบายเข้าใจได้ในภาษามนุษย์ ผู้ผลิตซอฟท์แวร์อาจเลือกอัลกอริธึมที่ไม่ได้ซับซ้อนมากเพื่อสามารถทำความเข้าใจได้ แต่ก็ต้องแลกกับความแม่นยำที่อาจะลดน้อยลงเพราะความซับซ้อนน้อยลง
ทางเลือกอีกทางหนึ่งของการตั้งกรอบกฎเกณฑ์ให้ Machine Learning ได้ทำงานอย่างมีประสิทธิภาพและไม่ก่อให้เกิดผลกระทบข้างเคียงที่ไม่ต้องการ คือเรื่องความรับผิดของอัลกอริธีม (Algorithmic Accountability) หลักการของมันคือการควบคุมการทำงานของโปรแกรมคอมพิวเตอร์ โดยที่องค์กรที่เป็นผู้นำเสนอผลิตภัณฑ์ที่มีอัลกอริธึมนั้นเป็นผู้รับผิดชอบผลกระทบของผลิตภัณฑ์นั้นเอง
ข้อดีของหลักการนี้คือ แทนที่จะพึ่งพาความเชี่ยวชาญของนักเขียนโปรแกรมหรือ Data Scientist ในการสร้างอัลกอริธึมให้แม่นยำ แต่ภาระและความรับผิดชอบขึ้นอยู่กับเจ้าของโปรแกรมหรือผลิตภัณฑ์นั้นๆ หากเป็นเช่นนี้แล้ว แทนที่จะเน้นไปที่การทำงานของอัลกอริธึมภายใน ความสำคัญจริงๆ คือการพิจารณาผลกระทบที่เกิดขึ้นของโปรแกรมคอมพิวเตอร์และคิดหาวิธีที่จะช่วยลดโอกาสหรือบรรเทาความผิดพลาดหากมีสิ่งไม่คาดคิดเกิดขึ้น
ดังนั้น ถ้าย้อนกลับไปในกรณีของ ACLU ข้างต้น หากประยุกต์หลักการนี้จะพบว่าควรมีมาตรการเพิ่มเติม เช่น มีผู้เชี่ยวชาญเข้ามาตรวจสอบความถูกต้องของการทำงานของโปรแกรมคอมพิวเตอร์ และยืนยันตัวตนจากฐานข้อมูลอื่นให้ชัดเจน เพื่อให้แน่ใจว่า ใบหน้าตัวอย่างกับฐานข้อมูลที่มีอยู่แม่นยำตรงกัน
แนวคิดทั้งสามด้านนี้มีจุดเด่นที่ต่างกันออกไป สุดท้ายแล้วขึ้นอยู่กับบริบทและวิธีใช้ของแต่ละองค์กร และภาคธุรกิจ หากผสมผสานความก้าวหน้าของเทคโนโลยีและการนำไปใช้ตามกรอบที่วางไว้อย่างชัดเจน นโยบายที่ปกป้องผลประโยชน์ของผู้บริโภคและเปิดโอกาสให้ภาคธุรกิจได้สร้างคุณค่าจากเทคโนโลยีใหม่นี้อย่างเต็มที่ เชื่อว่าจะเป็นแรงผลักดันเศรษฐกิจและสังคมในอนาคตอย่างแน่นอน
Tags: แอมะซอน, อัลกอริธึม, AI, Amazon, machine-learning


{kind=link}