





ทุกวันนี้ คำว่า ‘Big Data’ หรือข้อมูลขนาดใหญ่ ถูกหยิบมาใช้กันจนเฟ้อ อย่างไรก็ดี ในอดีตที่ผ่านมา ข้อมูลมีบทบาทสำคัญในการเปลี่ยนโลกมาแล้วหลายครั้งในหลายวงการ แม้ข้อมูลที่ใช้ในอดีตจะไม่ได้มีปริมาณมากมายมหาศาลเท่าปัจจุบันเพราะถูกจำกัดโดยความสามารถในการประมวลผลของคอมพิวเตอร์
ในบทความนี้ ผู้เขียนจะขอย้อนเวลากลับไปดูการวิเคราะห์บิ๊กดาต้าสามยุคสมัย ตั้งแต่ข้อมูลขนาดใหญ่เพื่อใช้ทางการแพทย์ที่ริเริ่มมาร่วม 70 ปีพอดิบพอดี การประยุกต์ข้อมูลเพื่อใช้ในแวดวงกีฬา และล่าสุด การวิเคราะห์ข้อมูลจากข้อความในทวิตเตอร์ เพื่อหาคำตอบว่า ข้อมูลเหล่านั้นสร้างคุณค่า และเปลี่ยนแปลงมุมมองของเราที่มีต่อโลกไปอย่างไรบ้าง
ดูใจกันยาวๆ ใน Framingham Heart Study
เมื่อวันที่ 12 เมษายน 1945 แฟรงคลิน ดี รูสเวลท์ (Franklin D. Roosevelt) ประธานาธิบดีคนที่ 32 ของสหรัฐอเมริกาเสียชีวิตด้วยโรคหัวใจ แต่การเสียชีวิตดังกล่าวไม่ใช่ว่าไร้ลางบอกเหตุ เพราะหนึ่งปีก่อนหน้านั้น ท่านประธานาธิบดีมีความดันโลหิตสูงถึง 210/120 และสองเดือนก่อนหน้าการเสียชีวิต มีความดันโลหิตสูงขึ้นอีกเป็น 260/150 แต่ความรู้ในขณะนั้นทำให้แพทย์ประจำตัวบอกกับท่านประธานาธิบดีว่า “เป็นเรื่องปกติสำหรับผู้ชายอายุประมาณนี้”
คำแนะนำดังกล่าวอาจทำให้แพทย์แผนปัจจุบันทำหน้าย่น เพราะแค่ความดันระดับ 210/120 แพทย์ก็อาจแจ้งให้คนไข้รีบเข้ารักษาตัวโดยด่วน แต่นั่นแหละครับ เรายังเข้าใจ ‘หัวใจ’ ของเราน้อยเกินไป
การตายของ FDR นำไปสู่แผนการศึกษาหัวใจขนานใจ ณ เมืองแฟรมิงแฮม (Framingham) ใน ปี 1948 โดยมีอาสาสมัครอายุ 30 – 59 ปีเข้าร่วมโครงการทั้งสิ้น 5,209 คน โดยอาสาสมัครจะต้องเข้าตรวจสุขภาพใจทุกๆ 2 ปี
ผ่านไปร่วม 40 ปี ผลผลิตจากข้อมูลจำนวนมหาศาลก็กลายเป็นแบบจำลองเพื่อทำนายความน่าจะเป็นที่เราจะป่วยเป็นโรคหลอดเลือดหัวใจในอีกสิบปีข้างหน้า โดยใช้ปัจจัยเสี่ยง เช่น ปริมาณคลอเรสตอรอลและน้ำตาลในเลือด ความดันโลหิต เพศ รวมถึงพฤติกรรมการสูบบุหรี่มาใช้ในการทำนาย
ฐานข้อมูลแฟรมิงแฮมถูกนำไปใช้ในการวิจัยกว่า 2,400 ชิ้น และยังเป็นก้าวแรกที่นำไปสู่การวิจัยเรื่องโรคหัวใจในชาติพันธุ์อื่นๆ (เนื่องจากลักษณะประชากรในแฟรมิงแฮมเป็นคนขาวชนชั้นกลาง) การค้นพบต้นเหตุของโรคหัวใจยังนำไปสู่การพัฒนายาขับปัสสาวะ (Diuretic) เพื่อลดความดันโลหิต และยาในกลุ่ม Statins ที่ใช้ลดคลอเรสเตอรอล
ชุดข้อมูลแฟรมิงแฮมทำให้ทั่วโลกเข้าใจโรคหัวใจมากขึ้น และลดอัตราการเสียชีวิตจากโรคหัวใจลงอย่างมีนัยสำคัญ นอกจากนี้ ยังกระตุ้นให้เกิดการศึกษาโรคหัวใจอย่างเป็นระบบทั่วโลก และมองหาปัจจัยอื่นๆ ที่อาจส่งผลต่อการเป็นโรคหัวใจที่คร่าชีวิตคนราว 17.3 ล้านคนต่อปี
รวยด้วยสถิติ ในวงการเบสบอล
Moneyball เป็นหนังสือท็อปฮิตติดชาร์ตเมื่อปี 2003 ต่อมามีคนนำมาทำเป็นภาพยนตร์ชื่อเดียวกันในปี 2011 เรื่องราวทั้งหมดว่าด้วยผู้จัดการทีมเบสบอล บิลลี บีน (Billy Beane) ที่มารับหน้าที่ดูแลทีมโอ๊คแลนด์ เอ (Oakland A’s) ซึ่งถูกตัดงบประมาณอย่างย่อยยับจนเรียกได้ว่าเป็นทีม ‘ราคาประหยัด’ ในวงการเบสบอลของอเมริกา ด้วยเงินเดือนเฉลี่ยต่อปีไม่ถึงครึ่งของทีมเบสบอลแนวหน้า
แน่นอนครับ แวดวงกีฬา ถ้ามีเงินถุงเงินถังก็มีโอกาสน้อยมากที่จะมีอัตราชนะต่ำ เนื่องจากผู้จัดการสามารถใช้เงิน ‘ฟาด’ เพื่อพานักกีฬาซูเปอร์สตาร์มารวมตัวกันในทีมเดียว แต่สิ่งที่ทำให้ทั้งวงการเบสบอลต้องจับตามอง โอ๊คแลนด์ เอ ก็เพราะทีมราคาประหยัดทีมนี้กลับมีผลงานเด่นล้ำนำหน้าแม้กระทั่งทีมที่ทุ่มเงินมหาศาลเพื่อซื้อตัวดาวเด่นในวงการเบสบอล
เคล็ดลับการเลือก ‘ของดีราคาถูก’ ของบิลลี บีน คือตัวเลขทางสถิติครับ
แรกเริ่มเดิมที แมวมองมีหน้าที่เสาะหานักกีฬาที่เข้าตาตามการแข่งขันระดับมัธยมปลายหรือมหาวิทยาลัย ซึ่งปัจจัยที่วงการเชื่อกันว่า ‘ดีเลิศ’ ก็ไม่พ้นความเร็วในการปาลูก และอัตราการตีโดนลูก นักเบสบอลที่มีสองทักษะนี้เป็นเลิศต่างก็ถูกแย่งชิงไปเข้าทีมในฐานะซูเปอร์สตาร์
บิลลีมองว่าทักษะดังกล่าวถูกตั้งราคาไว้ ‘สูงเกินควร’ จึงต้องการมองหาปัจจัยที่นำสู่ชัยชนะที่แท้จริง และได้ผู้ช่วยอย่าง พอล เดโปเดสตา (Paul DePodesta) บัณฑิตเศรษฐศาสตร์จากมหาวิทยาลัยฮาร์วาร์ด เป็นผู้ช่วยวิเคราะห์ข้อมูลของผู้เล่น รวมถึงคำนวณจำนวนคะแนนที่จำเป็นต่อการชนะ และจำนวนเกมส์ที่จะต้องชนะเพื่อพาทีมเข้าไปแข่งในเพลย์ออฟ
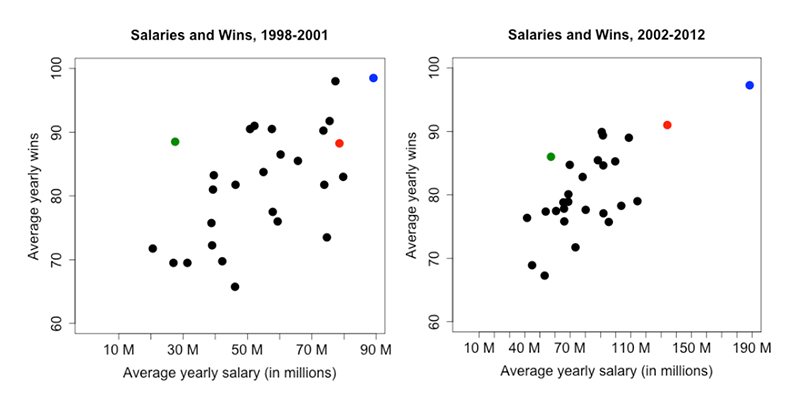
กราฟเปรียบเทียบค่าใช้จ่ายเงินเดือนเฉลี่ยของทีมโอ๊คแลนด์ เอ (จุดสีเขียว) กับทีมอื่นๆ ในเบสบอลลีก จะเห็นว่าระหว่างปี 1998 ถึง 2001 ทีมโอ๊คแลนด์ เอ มีจำนวนครั้งที่แข่งชนะสูงมากๆ หากเปรียบเทียบกับทีมอื่นๆ ที่มีค่าใช้จ่ายเงินเดือนเฉลี่ยใกล้เคียงกัน แต่ภายหลังเคล็ดลับถูกเปิดเผย จะเห็นว่าทุกทีมเคลื่อนเข้ามาเกาะกลุ่มกันมากขึ้น แม้ว่าโอ๊คแลนด์ เอ จะยังเป็นผู้นำด้านการใช้งบประมาณอย่างมีประสิทธิภาพ แต่ช่องว่างดังกล่าวก็แคบลงอย่างมาก ภาพจาก The Analytics Edge
หลังจากนำข้อมูลมากางและแกะด้วยโมเดลทางสถิติ บิลลีก็ได้คำตอบว่า ทักษะที่สำคัญที่สุดในการกำชัยชนะคือเปอร์เซ็นต์ที่ผู้เล่นอยู่บนเบส (On-Base Percentage: OBP) ซึ่งเป็นทักษะที่ถูกมองข้าม เมื่อได้คำตอบดังกล่าว โอ๊คแลนด์ เอ จึงกว้านซื้อตัวผู้เล่นตามคำแนะนำของแบบจำลอง
อย่างไรก็ดี เคล็ดลับ ก็ ‘ลับ’ อยู่ได้ไม่นาน เพราะหลังจากหนังสือ Moneyball ถูกตีพิมพ์เผยแพร่ ทุกทีมต่างก็หยิบเอาศาสตร์การวิเคราะห์ดังกล่าวมาปรับใช้กับทีมตัวเอง ส่วนโอ๊คแลนด์ เอ แม้ว่ายังมีประสิทธิภาพโดยเปรียบเทียบกับทีมอื่นๆ ที่ใช้งบประมาณใกล้เคียงกัน แต่ช่องว่างดังกล่าวก็ถูกบีบให้แคบลงอย่างเห็นได้ชัด
จับความรู้สึกสังคมด้วย Twitter
ทวิตเตอร์หรือเจ้านกสีฟ้า เป็นโซเชียลมีเดียที่มีผู้ใช้มากเป็นอันดับต้นๆ ของโลก โดยมีกลุ่มผู้ใช้หลากหลาย ตั้งแต่การประท้วงครั้งสำคัญ เช่น อาหรับสปริง หรือการรายงานวิกฤตการณ์และภัยธรรมชาติแบบเรียลไทม์ และที่ขาดไม่ได้ คือหลากหลายความคิดเห็นต่อผลิตภัณฑ์หรือบริการจากบริษัทยักษ์ใหญ่
จุดเด่นของทวิตเตอร์คือจำกัด 140 คำต่อข้อความ แต่ความยากในการใช้วิธีทางสถิติในการวิเคราะห์ทวิตเตอร์คือ ข้อมูลแทบไม่มีโครงสร้าง เต็มไปด้วยคำผิด และมีหลากหลายภาษา อีกทั้งยังมีปริมาณมหาศาลราว 500 ล้านทวีตต่อวัน จนแทบไม่มีทางที่มนุษย์จะวิเคราะห์ได้ด้วยตาเปล่า
ศาสตร์ในการแปลงภาษาคนให้เป็นภาษาคอมฯ เรียกว่าการประมวลผลภาษาธรรมชาติ (Natural language processing) คือการขยำขยี้ภาษาที่เราเห็นๆ กันอยู่นี่ให้คอมพิวเตอร์พอจะเข้าใจได้ว่าประโยคนั้นหมายถึงอะไร แต่ก็ยังมีความท้าทาย เช่น ความไม่ชัดเจนของรูปประโยคจากสรรพนามต่างๆ การเปรียบเปรย และการเสียดสี เพราะยากมากที่จะสอนให้คอมพิวเตอร์อ่าน ‘บริบท’ ให้ออก เพราะแม้แต่มนุษย์อย่างเราๆ ท่านๆ บางครั้งก็ยังไม่แน่ใจเลยด้วยซ้ำ
อย่างไรก็ดี ทวิตเตอร์ก็เป็นฐานข้อมูลขนาดใหญ่อันดับต้นๆ ที่หลายบริษัทเลือกใช้เพื่อจับความรู้สึกสังคม แต่เนื่องจากข้อจำกัดข้างต้น ก่อนที่จะนำข้อมูลดิบๆ มาวิเคราะห์ก็ต้องใช้มนุษย์ช่วย ‘ประเมิน’ ว่าข้อความดังกล่าวมีแนวโน้มเป็นลบ เป็นบวก หรือเป็นกลางกับบริษัท เช่น เว็บไซต์อย่าง Amazon Mechanical Turk แพลตฟอร์มที่จะรวบรวมเหล่าแรงงานหน้าจอคอมพิวเตอร์มาประเมินทัศนคติของข้อความในทวิตเตอร์ โดยได้รับค่าแรง 0.02 ดอลลาร์สหรัฐฯ ต่อหนึ่งข้อความ
ส่วนวิธีวิเคราะห์ที่ง่ายที่สุดจะใช้เทคนิคที่เรียกว่า Bag-of-words คือการหั่นประโยคทั้งประโยคออกเป็นคำ และพยายาม ‘ตัด’ คำที่ไม่จำเป็นออกไปและ ‘แต่ง’ คำให้ใกล้เคียงกันมากที่สุด ยกตัวอย่างเช่น
“บทความนี้ในโมเมนตัมดีมากเลยครับ ผมโคตรชอย แนะนำให้ลองอ่านกัน”
จากตัวอย่างทวีตที่เข้าข้างตัวเองด้านบน ลองพอเดาอารมณ์น่าจะได้เป็นบวกมากมาก ขั้นต่อไปเรามาลองแกะออกมาเป็นคำ จะได้ว่า ‘บทความ’ ‘นี้’ ‘ใน’ ‘โมเมนตัม’ ‘ดี’ ‘มาก’ ‘เลย’ ‘ครับ’ ‘ผม’ ‘โคตร’ ‘ชอย’ ‘แนะนำ’ ‘ให้’ ‘ลอง’ ‘อ่าน’ ‘กัน’ เสร็จแล้วก็ถึงขั้นตอนตัดและแต่ง
การตัด หมายถึงตัดคำที่ไม่จำเป็นออกไป หรือภาษาฝรั่งเรียกว่า ‘stop words’ คือมีหรือไม่มีก็ค่าเท่ากัน จากประโยคข้างต้น เราจะพอมองเห็นคำที่มักจะถูกใช้ในรูปประโยคทั่วไป ซึ่งควรถูกตัดออกก่อนการวิเคราะห์ เช่น ‘นี้’ ‘ใน’ ‘เลย’ ‘ครับ’ ‘ผม’ ‘กัน’ ส่วนการแต่ง หมายถึงพยายามปรับคำให้มีรูปแบบเหมือนๆ กัน เช่น ‘ชอย’ ซึ่งเป็นคำที่พิมพ์ผิดบ่อยจากคำว่า ‘ชอบ’ เราก็สามารถตั้งอัลกอริธึมให้ระบบมอง ‘ชอย’ มีค่าเท่ากับ ‘ชอบ’ ไปเลย ส่วนภาษาอังกฤษก็จะมีปัญหาเยอะหน่อยจากสารพัดการผัน ซึ่งแก้ไขโดยตั้งอัลกอริธึมให้ต้องหั่นคำเช่น argue argued argues arguing ให้เหลือ argu เพื่อให้คอมพิวเตอร์มองเห็นเป็นคำเดียวกัน
อย่างไรก็ดี วิธีดังกล่าวก็ยังไม่มีสูตรสมบูรณ์แบบ แต่ก็เพียงพอที่จะใช้ประกอบการสร้างแบบจำลองความรู้สึกของสังคม โดยผู้ใช้สามารถใส่ข้อมูลชุดใหม่ลงไปในแบบจำลอง เพื่อประเมินสถานการณ์แบบรายวัน (หรืออาจจะรายชั่วโมงด้วยซ้ำ) วิธีการเก็บรวบรวมข้อมูลจากอินเทอร์เน็ตนั้นประหยัดและรวดเร็วกว่าวิธีแบบดั้งเดิม เช่น การสำรวจความคิดเห็น แบบเทียบกันไม่เห็นฝุ่น
บริษัทสตาร์ตอัปอย่าง StockFluence ใช้การวิเคราะห์ในลักษณะดังกล่าวเพื่อประเมินราคาหุ้นในอีก 5 วันข้างหน้า หรือเว็บไซต์อย่าง Tweet Sentiment Visualization ที่แสดงแผนภาพอารมณ์ของ ‘คำ’ ที่เราค้นหา นอกจากนี้ ยังมีการวิจัยอีกหลายพันชิ้นที่นำวิธีการวิเคราะห์ในลักษณะดังกล่าวไปทำนายการขึ้นลงของราคาหุ้น ผลการเลือกตั้ง แม้แต่การแปลงวรรณกรรมเล่มหนาให้กลายเป็น Bag-of-words เพื่อหาปัจจัยที่ทำให้วรรณกรรมประสบความสำเร็จ
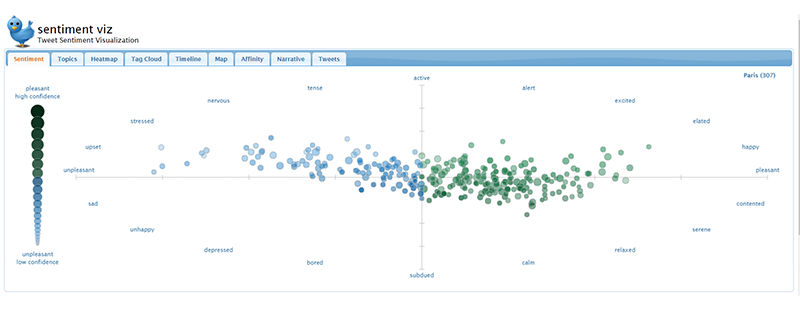
ผลการค้นคำว่า ‘Paris’ บนเว็บไซต์ Tweet Sentiment Visualization เมื่อวันที่ 13 พฤษภาคม 2561 จะเห็นว่าทวิตเตอร์ ณ ช่วงเวลาดังกล่าวมีการแสดงความเห็นค่อนไปทางตึงเครียดและวิตกกังวล เนื่องจากมีคนร้ายซึ่งกลุ่ม Islamic State (IS) อ้างว่าอยู่เบื้องหลัง ทำร้ายผู้คนบนท้องถนนทำให้มีผู้เสียชีวิต 1 ราย และบาดเจ็บ 4 ราย
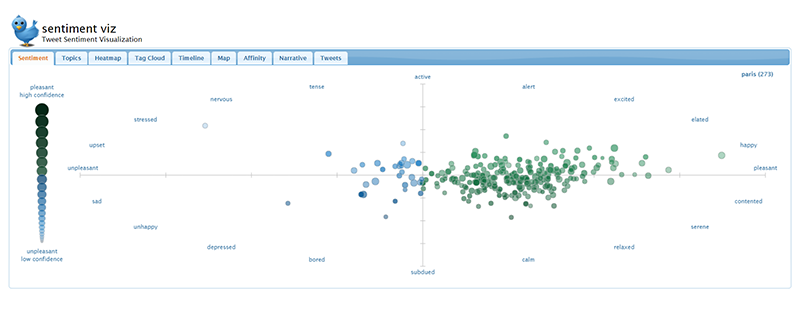
เมื่อลองค้นคำเดิม คือ คำว่า ‘Paris’ ในวันที่ 19 พฤษภาคม 2561 พบว่าอารมณ์ทางลบจะแตกต่างจากวันที่เกิดเหตุการณ์แทงกันที่ปารีสอย่างเห็นได้ชัด
เมื่อเครื่องมือทางสถิติถูกผสานกับเครื่องมือขนาดใหญ่ ย่อมสร้างแง่มุมที่แปลกใหม่ซึ่งมนุษย์อาจมองไม่เห็นได้ด้วยตาเปล่า แต่ก็ใช่ว่าจะ ‘ถูกและดี’ เสมอไป เพราะข้อมูลที่มีอยู่ในมืออาจเต็มไปด้วยอคติ และการใช้อัลกอริธึมอย่างไม่เข้าใจอาจนำไปสู่การตีความและตัดสินใจที่ผิดพลาด
ส่วนอคติดังกล่าวจะเลวร้ายขนาดไหน ผู้เขียนขอติดไว้ก่อนนะครับ แล้วจะมาเล่าต่อในอนาคตอันใกล้
เอกสารประกอบการเขียน
- The Framingham Heart Study and the Epidemiology of Cardiovascular Diseases: A Historical Perspective
- Moneyball: The Art of Winning an Unfair Game
- Sentiment Analysis: Concept, Analysis and Applications
- The Analytics Edge
Fact Box
สำหรับใครที่สนใจการวิเคราะห์โดยใช้ข้อมูลขนาดใหญ่ รวมถึงต้องการเข้าใจคำว่า Machine Learning แบบพื้นฐานผ่านประสบการณ์แบบคลุกกับข้อมูลจริงๆ ผู้เขียนแนะนำเป็นอย่างยิ่งว่าควรลงคอร์สออนไลน์ The Analytics Edge (ฟรี) ของมหาวิทยาลัย MIT ซึ่งจะวิเคราะห์ทั้ง 3 กรณีด้านบนผ่านชุดข้อมูลจริงๆ โดยใช้ R ซอฟต์แวร์ทางสถิติแจกฟรีที่ทรงพลังมาก เพราะนอกจากจะใช้วิเคราะห์ได้ไม่แพ้โปรแกรมราคาแพง ยังสามารถวาดกราฟข้อมูลได้สวยงามอีกด้วย



